

内存管理一节我也非常感兴趣。瀚海书香版主说的都是x86架构上的内存管理,各种的架构对内存的管理很大的不一样。像mips的内存管理就和X86有很大的不一样。内存管理这一章不深入理解下架构上的实现,总会有一些说不清道不明的感觉。


瀚海书香 发表于 2012-03-29 07:47
回复 20# 塑料袋
以塑料袋兄在硬件方面的知识,可以把mem/tlb cache这块顺便给大家说说
这种讨论太笼统,没有明确的议题,让人不知道从何说起
纯粹的讨论内存管理,个人感觉不能融会贯通地掌握内存管理的精华。
瀚海书香 发表于 2012-03-31 11:14
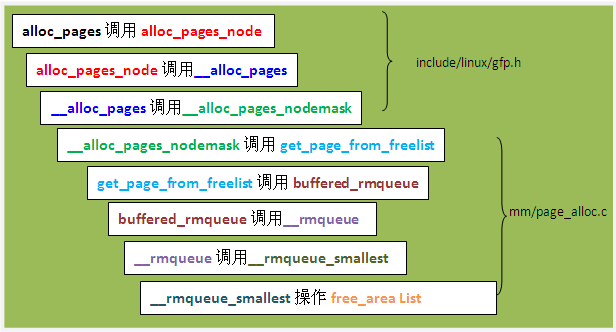
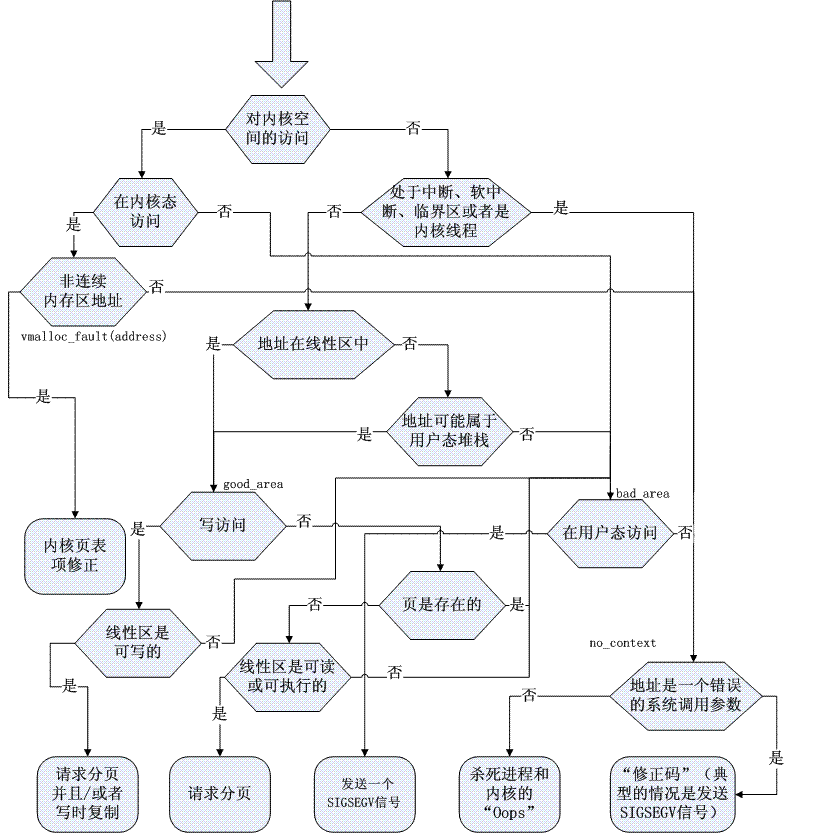
通过虚拟地址获取物理地址的代码

ARM_Linux_Course_17_Kernel_Memory_Management.PDF
496.02 KB, 下载次数: 236



ARM_Linux_Course_17_Kernel_Memory_Management.PDF
496.02 KB, 下载次数: 122
问个问题, Linux驱动模块是不是运行在 核心空间?

ARM_Linux_Course_17_Kernel_Memory_Management.PDF
TASK_SIZE 到 PAGE_0FFSET -1 区域是 Kernel module space ,这里应该是个bug吧。请确认?
顺便补充我的想法,我觉得应该那个区间是动态共享库的位置
ljzbq123 发表于 2012-04-04 21:09
在arm系统中,modules是放置在3G-16M~3G之间,如下linux 2.6.35的定义。
Memory.h (kernel\arch\arm\inc ...
瀚海书香 发表于 2012-04-04 20:30
回复 64# titer1
对应arm架构来说就是这样的,这块空间按Document的描述来说,的确是用于kernel module ...

我不讨论,只要包,行不?

比如32位的OS就只能支持3G左右的内存,所以就算你有N多的钱,买N多的内存,但受系统支持的限制,现在你也只能使用其中的3G内存
2.用户线程共享 进程的 用户空间,但是核心空间 堆栈是各自独立的
g__gle 发表于 2012-03-28 21:24
3.896M与高端内存
X86上Linux内核与进程共用地址空间,另外,内核所有的地址空间被设计成与内存固定映射。
结果是:内核拥有的地址空间很小(因为用户态占了大部分);
能灵活使用的虚拟地址不多(因为大部分要与物理内存做一一对应的关联)。
于是,内核能使用物理内存的大小被其狭小的虚拟地址空间所限制了。
即便有再多的物理内存,内核已没有多余的虚拟地址与之映射,从而无法访问。
所以,896M用于与物理内存建立一一对应关系,
剩余的虚拟地址空间,分时映射没能被896M覆盖到的物理内存,这部分物理内存就是高端内存。
...
g__gle 发表于 2012-03-28 21:24
以前看APUE,以为mmap是个trick十足的系统调用。
后来才明白,如果不理解内核的cache系统,mmap的作用很难理解。
...
瀚海书香 发表于 2012-04-12 14:42
回复 88# titer1
这个或许有用http://linux.sheup.com/linux/38/linux21081.htm
1、 page cache及swap c ...

| 欢迎光临 Chinaunix (http://bbs.chinaunix.net/) | Powered by Discuz! X3.2 |
