QQ截图20140521214656.png (4.1 KB, 下载次数: 62)
下载附件
2014-05-21 21:47 上传
q1208c 发表于 2014-05-22 08:33 perl怕是不行了.
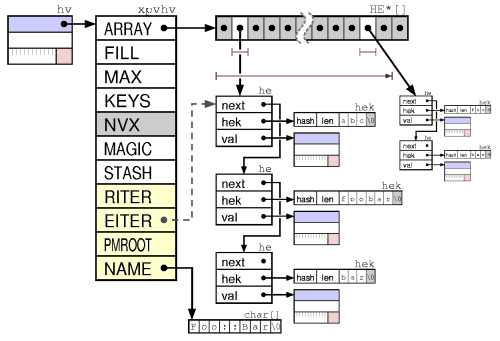
1.png (25.97 KB, 下载次数: 11)
2014-05-27 16:38 上传
3.png (2.93 KB, 下载次数: 12)
2014-05-27 16:52 上传
2.png (4.7 KB, 下载次数: 11)

 我以前在linux/unix上是用sort 按指定列排序,然后去重
我以前在linux/unix上是用sort 按指定列排序,然后去重