 免费注册
免费注册
|
查看新帖 | | |
|
|
| 平台 论坛 博客 文库 | |
 楼主: send_linux
楼主: send_linux
|



[使用帮助] 自动化运维技术讨论之----运维监控如何帮你提前发现故障(获奖名单已公布-2013-7-31) [复制链接] |
  |
| |
|
|
||
|
| |
|
|
||
          |
| |
|
|
||
  |
| |
|
|
||
|
| |
|
|
||
|
| |
|
|
||
 |
| |
|
|
||
|
| |
|
|
||
     |
| |
|
|
||
     |
| |
|
|
||
北京盛拓优讯信息技术有限公司. 版权所有 京ICP备16024965号-6 北京市公安局海淀分局网监中心备案编号:11010802020122 niuxiaotong@pcpop.com 17352615567
未成年举报专区
中国互联网协会会员 联系我们:huangweiwei@itpub.net
感谢所有关心和支持过ChinaUnix的朋友们 转载本站内容请注明原作者名及出处
| 清除 Cookies - ChinaUnix - Archiver - WAP - TOP |



 发表于 2013-07-13 15:46
发表于 2013-07-13 15:46


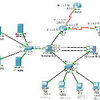




 发表于 2013-07-24 19:33
发表于 2013-07-24 19:33
