 Ãâ·Ñ×¢²á
Ãâ·Ñ×¢²á
|
²é¿´ÐÂÌû | | |
|
|
| ƽ̨ ÂÛ̳ ²©¿Í ÎÄ¿â | |
 Â¥Ö÷: titansword2000
Â¥Ö÷: titansword2000
|



ÌìÁ¿Êý¾ÝÈçºÎ´¦Àí£¿ [¸´ÖÆÁ´½Ó] |
|
| |
|
|
||
|
| |
|
|
||
|
| |
|
|
||
|
| |
|
|
||
          |
| |
|
|
||
|
| |
|
|
||
|
| |
|
|
||
|
| |
|
|
||
|
| |
|
|
||
|
| |
|
|
||
±±¾©Ê¢ÍØÓÅѶÐÅÏ¢¼¼ÊõÓÐÏÞ¹«Ë¾. °æȨËùÓÐ ¾©ICP±¸16024965ºÅ-6 ±±¾©Êй«°²¾Öº£µí·Ö¾ÖÍø¼àÖÐÐı¸°¸±àºÅ£º11010802020122 niuxiaotong@pcpop.com 17352615567
δ³ÉÄê¾Ù±¨×¨Çø
Öйú»¥ÁªÍøлá»áÔ± ÁªÏµÎÒÃÇ£ºhuangweiwei@itpub.net
¸ÐлËùÓйØÐĺÍÖ§³Ö¹ýChinaUnixµÄÅóÓÑÃÇ ×ªÔر¾Õ¾ÄÚÈÝÇë×¢Ã÷Ô×÷ÕßÃû¼°³ö´¦
| Çå³ý Cookies - ChinaUnix - Archiver - WAP - TOP |


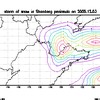
 ·¢±íÓÚ 2012-02-24 16:14
·¢±íÓÚ 2012-02-24 16:14


 ÕâÑù°É£¬ÎÒ½«ÎÊÌâÔÙÃèÊöÏ°ɡ£
ÕâÑù°É£¬ÎÒ½«ÎÊÌâÔÙÃèÊöÏ°ɡ£