|
ĽŮĹĪ”√Ľß£ļ
«Žīůľ“ľį Ī’ĺńŕ∂Ő–ŇŃ™ŌĶő“Ň∂ ∑ĘňÕ◊‘ľļĶń◊Ó–¬łŲ»ň–ŇŌĘļÕ” ľńĶō÷∑
ĽįŐ‚Ī≥ĺį£ļ
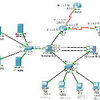
∑÷≤ľ ĹĽķ∆ų—ßŌį «ňś◊Ňīů żĺ›ļÕĽķ∆ų—ßŌįĶń∑Ę’Ļ∂Ý–ň∆ūĶń°£‘ŕīů żĺ›ĶńīůŃŅ”¶”√«į£¨—–ĺŅ’Ŗ÷¬Ń¶”ŕ—–ĺŅŐŠłŖĽķ∆ų—ßŌįĶń∑Ĺ∑®£¨÷ų“™ Ļ”√∂ŗłŲī¶ņŪ∆ųĹÝ––Ļ§◊ų£¨’‚ņŗň∆”ŕ“Ľ÷÷°į≤Ę––ľ∆ň„°ĪĶń∑Ĺ Ĺ£¨Õ®Ļż»őőŮĶń≤ūĹ‚°Ę∑÷Ňšī¶ņŪĶ•‘™ļÕĻť≤ĘĶń∑Ĺ ĹĹÝ––ī¶ņŪ°£∑÷≤ľ Ĺ»ňĻ§÷«ń‹ŌĶÕ≥Ņ…“‘ī”īů żĺ›÷–◊‹ĹŠĻś¬…£¨Ļťń…’ŻłŲ»ňņŗĶń÷™ ∂Ņ‚£¨Õ®Ļż∑÷≤ľ ĹĽķ∆ų—ßŌįĹ®ŃʔԓŚ—ßŌįŌĶÕ≥£¨Õ®Ļż∑÷≤ľ ĹĶń∑Ĺ Ĺ£¨ī”…Ō«ß“ŕĶńőńĪĺļÕīůĻśń£Ķń”√Ľß żĺ›÷–ĹÝ––Ľķ∆ų—ßŌį£¨Ļťń…ļļ”Ô”Ô“Ś£¨–ő≥…ŌŗĻō–‘Ķń—ĶŃ∑ń£–Õ°£ňŁŅ…“‘‘ŕ“ĽļŃ√Ž÷ģńŕĹ‚őŲ”Ôĺš£¨ņŪĹ‚∆Á“Ś£¨ĹęĻ„łśŌĶÕ≥°Ęň—ňų“ż«ś°ĘÕ∆ľŲŌĶÕ≥ĶńņŪĹ‚ń‹Ń¶īů∑ý∂»ŐŠ…ż°£Ľķ–ĶĻ§“Ķ≥Ųįś…Á≥ŲįśĶń°∂∑÷≤ľ Ĺ»ňĻ§÷«ń‹£ļĽý”ŕTensorFlow°ĘRTOS”Ž»ļŐŚ÷«ń‹ŐŚŌĶ°∑“Ľ ť∂‘∑÷≤ľ Ĺ»ňĻ§÷«ń‹ĶńŌŗĻō÷™ ∂◊ŲŃňŌĶÕ≥Ĺ≤ Ų£¨ĪĺīőĽÓ∂ĮĪ„ «“‘īňő™∆űĽķ£¨ļÕłųőĽ»ňĻ§÷«ń‹ľľ űįģļ√’ŖĺÕŌŗĻōĽįŐ‚’ĻŅ™Ő÷¬Ř£¨Ľ∂”≠īůľ“”Ľ‘ĺ∑Ę—‘°£
Īĺ∆ŕĽįŐ‚£ļ
£®1£©‘ŕ…Ó∂»—ßŌį÷–£¨≥£”√”ŕ—ĶŃ∑ľ”ňŔĶń∑Ĺ∑®”–ńń–©£Ņ»ÁļőÕ®Ļż∑÷≤ľ ĹĶń∑Ĺ Ĺ∂‘…Ó∂»—ßŌįĶń≤ő ż—ĶŃ∑ĹÝ––īůĻśń£ľ”ňŔ£Ņ £®2£©‘ŕ«ŅĽĮ—ßŌį∑Ĺ√ś£¨»Áļőī¶ņŪ∂ŗłŲ÷«ń‹ŐŚ–≠Õ¨ĺŲ≤Ŗ£Ņ»Áļő‘ŕłī‘”ĶńĽ∑ĺ≥Ō¬’“≥Ų≥§∆ŕ¬∑ĺ∂Ō¬Ķń◊Ó”Ň≤Ŗ¬‘£Ņ £®3£©‘ŕ”őŌ∑Ņ™∑ĘŃž”Ú£¨≥£”√Ķń»ňĻ§÷«ń‹ň„∑®”–ńń–©£ŅńķĺűĶ√ł√»Áļő»•īÚ‘ž“ĽłŲMOBA”őŌ∑Ķńň„∑®ĹŠĻĻ£Ņ
ľőĪŲĹť…‹£ļ
Õűĺ≤“› …ŮÕ√őīņīŅ∆ľľ”–ŌřĻęňĺ/ńßĺ≥ ņĹÁŅ∆ľľ”–ŌřĻęňĺīī ľ»ň£¨÷–Ļķ…Ő“ĶŃ™ļŌĽŠ÷«Ņ‚◊®ľ“£¨÷–Ļķľ∆ň„Ľķ—߼ŠĽŠ‘Ī£¨ACMĽŠ‘Ī£¨÷–Ļķ ż◊÷∑¬’ś–≠ĽŠ◊®ľ“őĮ‘Ī°£‘Ýĺ≠»ő÷į”ŕőšļļ÷–Őķ«ŇŃļŅ∆—ß—–ĺŅ‘ļ°Ę…Ōļ£Ń™ŌŽ—–ĺŅ‘ļļÕĽ™ő™—–ĺŅňý£¨»ő—–ĺŅ‘Ī°£‘Ýő™QQžŇőŤ1ļÕ2“ż«śŅ™∑ĘĻ§≥Ő ¶ľįŅÕĽß∂ňłļ‘ū»ň£¨Ķŕ“Ľ ”∆Ķ—–ĺŅ‘ļ£®CCF«ÝŅťŃī◊®őĮĶ•őĽ£©—–ĺŅ‘ĪļÕľľ ű◊‹ľŗ£¨≤ľĪ»«ÝŅťŃī£®BUMO£©ĻęŃīľ‹ĻĻ ¶£¨◊ň√ņŐ√Ņ∆ľľľĮÕŇīů żĺ›÷––ńľľ ű◊‹ľŗ°£Ō÷ő™÷–ĻķĹ®…Ť“Ý––Ĺ®–ŇĹū»ŕŅ∆ľľĽýī°ľľ ű÷––ń»ňĻ§÷«ń‹∆ĹŐ®◊®ľ“°Ęľ‹ĻĻ ¶ļÕ—–ĺŅ‘Ī£¨ī” ¬īů żĺ›°Ę∑÷≤ľ Ĺ»ňĻ§÷«ń‹ļÕ«ÝŅťŃī÷«ń‹ÕݬÁĶ»Ńž”ÚĶń—–ĺŅĻ§◊ų°£÷Ý”–°∂Unity”ŽC ÕݬÁ”őŌ∑Ņ™∑Ę Ķ’Ĺ£ļĽý”ŕVR°ĘAI”Ž∑÷≤ľ Ĺľ‹ĻĻ°∑ľį°∂«ÝŅťŃī”ŽĹū»ŕīů żĺ›’ŻļŌ Ķ’Ĺ°∑Ķ»Õľ ť°£‘ŕ«ÝŅťŃī”Ž∑÷≤ľ Ĺ»ňĻ§÷«ń‹Ńž”Ú∑ĘĪŪ∂ŗ∆™ŌŗĻō¬Řőń≤ĘĽŮĹĪ£¨≤Ę”Ķ”–∂ŗŌÓľľ ű◊®ņŻ°£
Īĺ∆ŕĹĪ∆∑£ļ
◊Óľ—Ľżľę≤ő”Žĺ≠—ť∑÷ŌŪĹĪ5√Ż£¨łųĹĪņÝľŘ÷Ķ169‘™Ķń°∂∑÷≤ľ Ĺ»ňĻ§÷«ń‹£ļĽý”ŕTensorFlow°ĘRTOS”Ž»ļŐŚ÷«ń‹ŐŚŌĶ °∑Õľ ť1Īĺ°£
∑÷≤ľ Ĺ»ňĻ§÷«ń‹£ļĽý”ŕTensorFlow°ĘRTOS”Ž»ļŐŚ÷«ń‹ŐŚŌĶ Õűĺ≤“› ÷Ý ťļŇ£ļ978-7-111-66520-5 ”°’Ň£ļ34.25£®őń«į12“≥£¨’żőń536“≥£¨0łŲĻ„łś“≥£¨Ļ≤548“≥£© ∂®ľŘ£ļ169.00‘™ …Ōľ‹£ļľ∆ň„Ľķ/»ňĻ§÷«ń‹
≤ő”Ž∑Ĺ Ĺ£ļ
÷ĪĹ”‘ŕł√÷ųŐ‚Ō¬ĽōŐŻľīŅ…°£
ĽÓ∂Į Īľš£ļ
2021ńÍ6‘¬21»’-2021ńÍ7‘¬20»’
Õľ ťĻļ¬Ú£ļ
|  √‚∑—◊Ę≤Š
√‚∑—◊Ę≤Š








































 ∑ĘĪŪ”ŕ 2021-06-21 09:48
∑ĘĪŪ”ŕ 2021-06-21 09:48


 ∑ĘĪŪ”ŕ 2021-06-21 22:20
∑ĘĪŪ”ŕ 2021-06-21 22:20